Towards principled evaluations of sparse autoencoders for interpretability and control
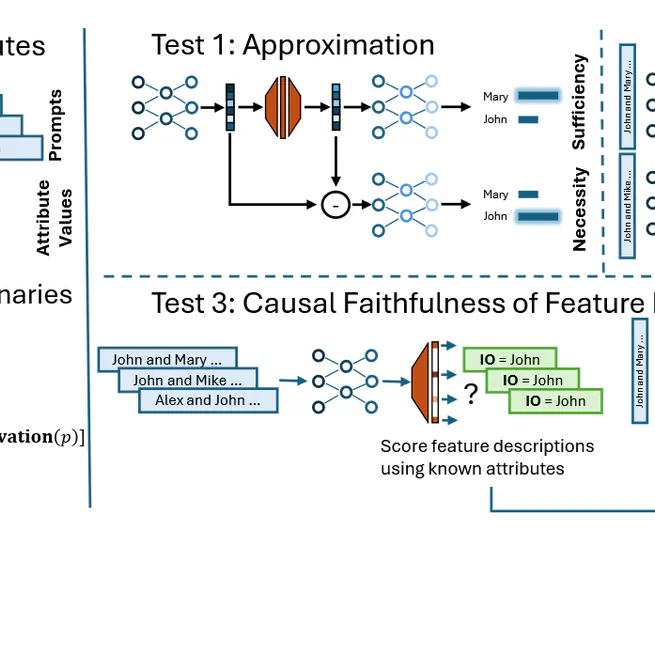
We propose a framework for evaluating sparse dictionary learning methods in mechanistic interpretability by comparing them against supervised feature dictionaries. Using the indirect object identification task as a case study, we show that while sparse autoencoders can capture interpretable features, they face challenges like feature occlusion and over-splitting that limit their effectiveness for model control compared to supervised approaches.
Apr 9, 2025
Is This the Subspace You Are Looking For? An Interpretability Illusion for Subspace Activation Patching
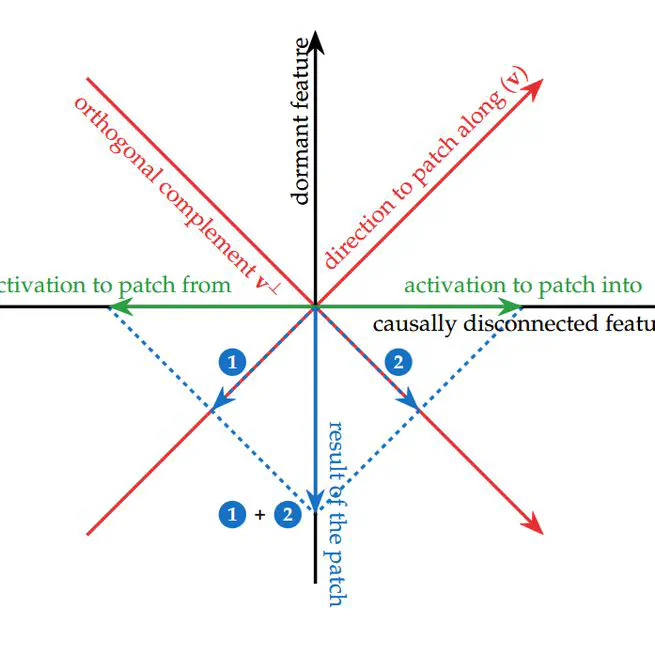
We show that subspace interventions in mechanistic interpretability can be misleading - even when they successfully modify model behavior, they may do so by activating alternative pathways rather than manipulating the intended feature. We demonstrate this phenomenon in mathematical examples and real-world tasks, while also showing what successful interpretable interventions look like when guided by prior circuit analysis.
May 9, 2024