Towards principled evaluations of sparse autoencoders for interpretability and control
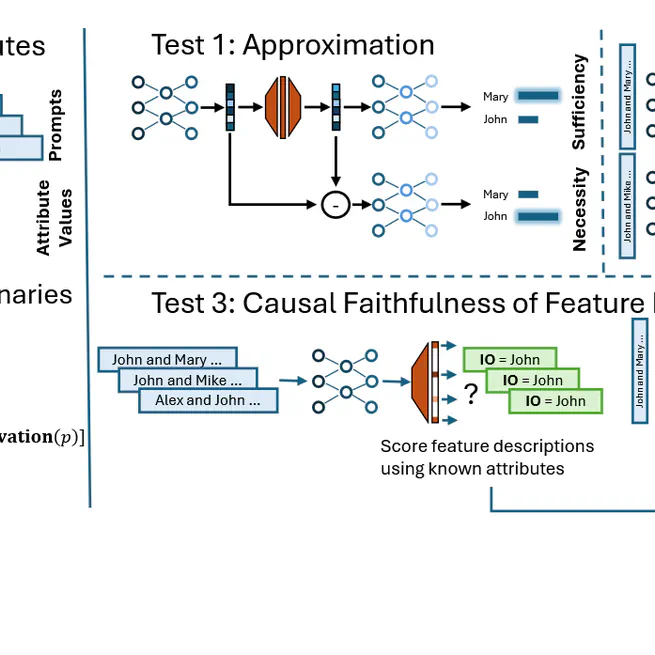
We propose a framework for evaluating sparse dictionary learning methods in mechanistic interpretability by comparing them against supervised feature dictionaries. Using the indirect object identification task as a case study, we show that while sparse autoencoders can capture interpretable features, they face challenges like feature occlusion and over-splitting that limit their effectiveness for model control compared to supervised approaches.
May 14, 2024